
January 24, 2025
4 minutes




synthetic data in market research
data privacy in research
improve research accuracy
synthetic insights
privacy-preserving analytics
In an era of rising privacy concerns, regulatory scrutiny, and global data protection laws, collecting and analyzing real-world data has become more complicated—and more risky. At the same time, brands and institutions are under pressure to act faster, go deeper, and serve increasingly complex audience needs.
This tension between data accessibility and data responsibility has given rise to one of the most powerful tools in modern research: synthetic data.
When implemented correctly, synthetic data doesn't just safeguard privacy—it enhances accuracy, unlocks scale, and reduces bias. In this post, we’ll break down how this technology works, where it fits into today’s insight workflows, and why it’s becoming essential for responsible, future-proof research.
Synthetic data is artificially generated information that mimics the statistical structure and behavior of real-world datasets—without revealing any actual respondent identities.
Using advanced statistical and machine learning models, synthetic data is created to reflect real-world correlations, distributions, and patterns. The output behaves as if it came from real people, yet it contains no personal or identifying information.
This isn’t simulation for simulation’s sake. At DataDiggers, our synthetic data solutions—Syntheo and Correlix—are built to help organizations:

Contrary to what some may assume, synthetic data—when developed and validated properly—can increase the accuracy of your insights, not reduce it.
Here’s how:
In many real-world datasets, some groups are underrepresented or missing altogether. Whether due to recruitment limitations, survey fatigue, or privacy hesitancy, this leads to sampling bias.
With Correlix, we use advanced models to augment these datasets by creating synthetic counterparts that preserve the statistical integrity of the total population—resulting in more balanced, complete, and actionable data.
Even with best-in-class validation tools like Research Defender or IPQS, fraud, inattentiveness, and disengagement can distort results. Synthetic data offers a clean alternative for modeling behaviors and outcomes without depending on potentially contaminated inputs.
This is especially valuable in exploratory studies, where directional accuracy matters more than individual verbatim inputs.
Using Syntheo, researchers can simulate different audience reactions, behavioral models, or segmentation strategies across thousands of variables—all without compromising data quality.
Whether you're stress-testing messaging, assessing product-market fit, or exploring cultural nuance, synthetic personas let you evaluate outcomes in a fully controlled, replicable environment.
Regulations like the GDPR, CCPA, and other global frameworks mandate that organizations handle personal data with utmost care. Noncompliance is not just a legal risk—it’s a reputational one.
Synthetic data solves this at the root:
At DataDiggers, we treat synthetic datasets as privacy-first by design. Whether you're augmenting an existing survey or modeling new audiences entirely, our processes ensure that your insight engine runs without ever putting respondent identity at risk.
Synthetic data doesn’t replace real-world inputs—it complements them. Here’s where it adds most value:
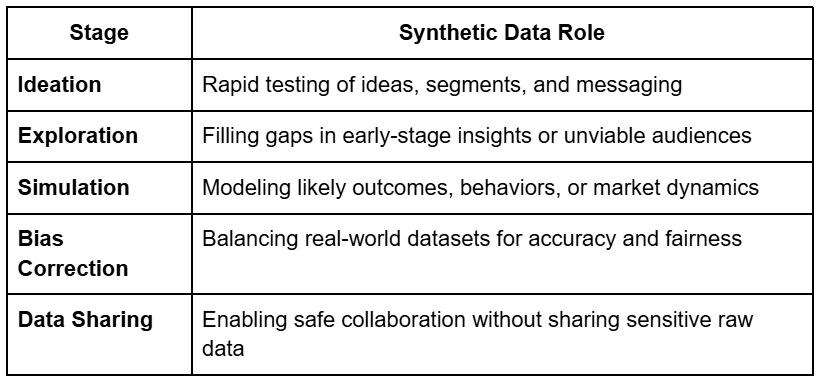
As data becomes both more powerful and more regulated, forward-thinking brands are rethinking their insight strategy. Accuracy and privacy don’t have to be tradeoffs. With tools like Syntheo and Correlix, you can expand your learning potential and reduce risk—at the same time.
At DataDiggers, we’re helping clients around the globe build smarter, faster, and more ethical research pipelines using synthetic data.
Interested in exploring what synthetic data could do for your next project?
Reach out today to learn how Syntheo and Correlix can strengthen your research strategy—without compromising on quality or compliance.
Download The Bias-Free Data Guide — get faster, higher-quality insights.







