
January 16, 2025
4 minutes




bias correction in market research
Correlix vs weighting
synthetic data vs post-stratification
Bias is a persistent challenge in market research, especially when dealing with underrepresented groups, hard-to-reach segments, or legacy datasets. For decades, post-stratification weighting has been the go-to solution. But as data complexity and expectations for fairness grow, new approaches—like synthetic data generation with Correlix—offer more flexible, powerful alternatives.
So how do the two compare? And how should researchers decide which to use?
This article walks you through the strengths, limitations, and ideal use cases for both traditional weighting and Correlix, our advanced solution for bias correction through synthetic augmentation.
A statistical technique where collected responses are reweighted after fieldwork to better reflect known population distributions (e.g., age, gender, region). Often used in survey research to compensate for sample imbalance.

A DataDiggers solution that uses statistical modeling and machine learning to simulate missing or underrepresented data segments, creating high-integrity synthetic records that reflect real-world patterns while correcting for sample skew.
Both methods aim to align your dataset with reality—but they go about it in fundamentally different ways.
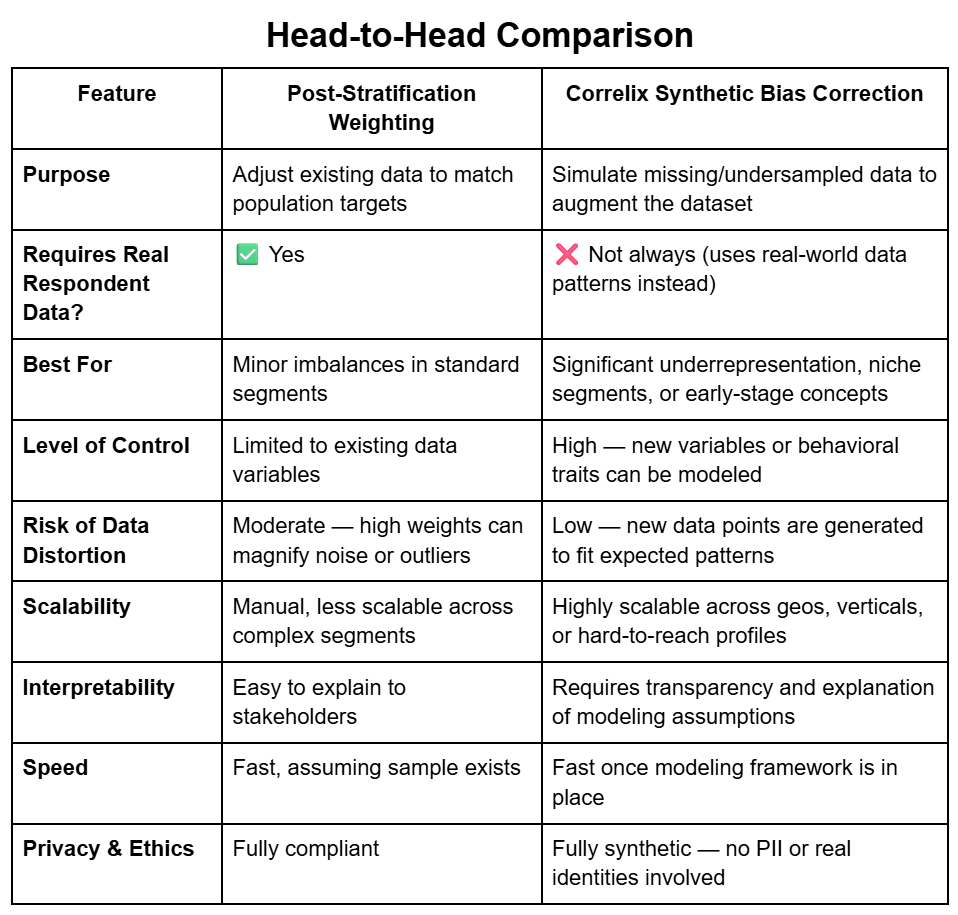
Post-stratification weighting is a sound and proven method—especially when:
✅ Your sample is largely representative, with only small imbalances
✅ You’re adjusting across known demographic variables like age, gender, or location
✅ You want to preserve the original respondent base without adding synthetic data
✅ You’re working on standardized, large-sample projects where quotas were mostly met
⚠️ But keep in mind: high weights on small groups can distort the data, inflate variance, or give too much influence to too few respondents.
Correlix becomes essential when:
✅ You’re missing entire audience segments or can’t access them at all
✅ You're working with early-stage products or niche markets where no real data exists
✅ Traditional quotas failed to fill, and the remaining data is heavily skewed
✅ You want to test multiple “what-if” scenarios or simulate behaviors beyond existing data
✅ Data privacy, cost, or time constraints prevent real-world re-fielding
In these cases, generating high-fidelity synthetic records using Correlix not only restores balance but also expands your insight scope.
Let’s say you’re researching AI adoption in healthcare. Your collected sample skews heavily toward large urban hospitals, missing rural clinics entirely.

Here’s the key: you don’t have to choose one over the other. In many studies, they work better together.
Bias correction is evolving. While post-stratification still has its place, synthetic augmentation is the future—especially as research enters more fragmented, fast-moving, and complex territories.
At DataDiggers, we’ve built Correlix not just to simulate data—but to support smarter, fairer, more adaptive research across industries.
Ready to explore which bias correction method best suits your study?
Get in touch and we’ll help you find the right mix of tools for your specific goals.
Download The Bias-Free Data Guide — get faster, higher-quality insights.







